Diferencias de género en la Wikipedia española (II)
13 febrero, 2020 wikipedia-uoc-1080×675
wikipedia-uoc-1080×675Vamos a empezar a resolver el ejercicio que dejamos pendiente en una entrada anterior sobre las diferencias de género existentes en la Wikipedia en español. El objetivo es mostrar cómo manipular los dumps de Wikipedia usando diferentes instrucciones y herramientas desde la línea de comandos del sistema operativo para analizar aspectos como las desigualdades de género presentes.
En nuestro caso hemos utilizado como entorno de trabajo un ordenador MacBook Pro con el sistema operativo macOS, con diferentes extensiones (herramientas) que ya iremos introduciendo cuando sean requeridas, pero debería ser posible realizar las mismas operaciones en diferentes entornos.
El primer paso, sencillo de ejecutar pero costoso en tiempo, es descargar el último dump de la Wikipedia en español, y lo hacemos mediante el uso de la herramienta wget desde la línea de comandos:
wget https://dumps.wikimedia.org/eswiki/latest/eswiki-latest-stub-meta-history.xml.gz
En nuestro caso, en el momento de ejecutar este comando la última versión del dump hacía referencia al día 02/02/2020 y se trata de un fichero comprimido .gz de unos 7,5 GB, el cual puede tardar varios minutos en descargarse, dependiendo de la velocidad de descarga. A unos 5 MB/s esto significa casi 26 minutos, así que no se trata de un fichero que se tenga que ir moviendo de sitio continuamente.
Una vez descargado el fichero, procedemos a descomprimirlo con gunzip y mucha paciencia:
gunzip -d https://dumps.wikimedia.org/eswiki/latest/eswiki-latest-stub-meta-history.xml.gz
Después de un buen rato, esto genera un fichero con extensión .xml que ocupa unos 50 GB, por lo que habrá que tener suficiente espacio en disco para realizar estas dos operaciones. Al descomprimir el fichero .gz completamente, éste es eliminado automáticamente.
El siguiente paso es recorrer el fichero .xml con todas las ediciones para convertirlo a un formato más sencillo de manipular, simplificando tanto su estructura como el contenido que queremos analizar. En nuestro caso queremos saber quién edita qué, cómo y cuándo, por lo que nos limitaremos a procesar esta información.
Usando el comando more podemos paginar por su contenido, hasta localizar por ejemplo la página de Andorra (mediante la opción de búsqueda, presionando la tecla “/” y buscando Andorra):...<title>Andorra</title> <ns>0</ns> <id>7</id> <revision> <id>18</id> <timestamp>2001-09-02T19:02:54Z</timestamp> <contributor> <username>Cdani</username> <id>461041</id> </contributor> <comment>*</comment> <model>wikitext</model> <format>text/x-wiki</format> <text bytes="450" id="18" /> <sha1>smbbybh6rvhmvqsht45r3tacb4jct81</sha1> </revision> <revision>
…
Este fichero no contiene las páginas de Wikipedia, “tan solo” las ediciones realizadas, que es lo que nos interesa; para analizar el contenido deberíamos usar otros ficheros que forman parte del dump de Wikipedia. Como se puede ver, una página contiene una revisión tras otra (encerradas entre parejas <revision>…</revision>), ordenadas cronológicamente mediante un timestamp. En este caso un usuario llamado Cdani creó la página (por tratarse de la primera revisión) el día 02/09/2001 a las 19:02:54 y añadió un contenido de 450 bytes. Lo que quisiéramos tener es un fichero plano, con una línea de texto para cada edición, de forma parecida a esto:
Andorra 20010902190254 Cdani 450
…
Es decir, un fichero con cuatro columnas separadas por espacios, conteniendo la página editada, la fecha de la edición, el nombre del usuario que ha hecho la edición y el número de bytes resultante de la edición realizada. Este paso intermedio podría evitarse y realizar el análisis usando directamente el fichero xml, pero lo haremos de esta manera para ejemplificar las posibilidades del sistema operativo por lo que respecta a la manipulación de ficheros mediante programación en scripting.
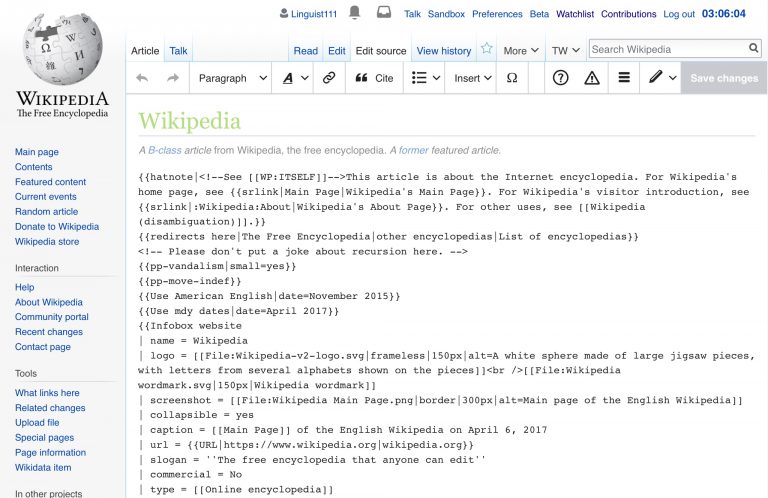
Podemos recorrer el fichero xml de diferentes maneras, pero siempre es mejor reutilizar algún módulo o librería que nos simplifiquen dicha tarea. En este caso, el siguiente código python usa la librería mw (MediaWiki Utilities) para obtener este resultado deseado:
from mw import xml_dumpfrom mw.xml_dump import Iterator import re file = "./eswiki-latest-stub-meta-history.xml" dump = Iterator.from_file(open(file)) for page in dump: if (page.redirect is None): for revision in page: if (revision.contributor.user_text): qui=revision.contributor.user_text.replace(' ','_') else: qui="SINUSUARIO" print(page.title.rstrip().replace('','_'),revision.timestamp,qui,revision.text.bytes)
Básicamente, este script abre el fichero especificado, y crea un dump como un iterador que nos permitirá recorrerlo. Entonces, para cada página del dump, si no se trata de una redirección, se recorren todas las revisiones en la página, se sustituyen los espacios en blanco en el nombre del usuario por un guión bajo (usaremos el espacio como separador) en caso de que exista y, finalmente, imprime los campos deseados, cambiando también los espacios del título por guiones bajos, tal y como lo hace la Wikipedia.
Para ejecutar este script podemos usar una opción muy adecuada que nos permite el sistema operativo, la cual consiste en ejecutarlo en background, de forma que podamos ver cómo se va ejecutando el script y la salida que va generando:
nohup python3 ediciones.py > ediciones.temp_0 &
Esto nos permite “desconectar” el subproceso de forma que aunque cerremos la sesión éste se seguirá ejecutando. Esto es interesante para procesos que tardan mucho, y que no requieren interacción con el usuario.
Con nohup y “&” lo que hacemos es ejecutar en segundo plano el script (en el ejemplo está guardado en un fichero llamado ediciones.py) con el intérprete de python en su versión 3.X (no funciona con la versión 2.7), y con “>” redirigir la salida a un fichero llamado ediciones.temp_0, el cual podemos interrogar con el comando tail para ver cómo va creciendo:
tail ediciones.temp_0
lo que retorna, por ejemplo:
Siglo_XIX 20140903185746 148.216.45.240 34722Siglo_XIX 20140903185753 PatruBOT 34676Siglo_XIX 20140914022908 186.159.1.131 34435Siglo_XIX 20140915034019 DonBarredora 34676Siglo_XIX 20140924104057 190.43.233.47 34682Siglo_XIX 20140924105839 Arjuno3 34676Siglo_XIX 20140926202847 190.250.166.52 34687Siglo_XIX 20140926203038 190.250.166.52 34664Siglo_XIX 20140926203142 Technopat 34676
…
Ya podemos empezar a ver algunos de los temas a resolver antes de nuestro análisis, relacionados con los usuarios que realizan ediciones. En primer lugar, hay muchas ediciones realizadas de forma anónima, donde sólo es posible saber la dirección IP desde la cual se realizó la edición, pero nada más, por lo que éstas deberán ser descartadas. Por otra parte, hay ediciones realizadas por bots, como PatruBOT, el cual sabemos que es un bot porque incluye BOT (o una variación) en su nombre y, realmente, porque aparece en la categoría de bots de Wikipedia. Los bots no son usuarios reales y también los eliminaremos para quedarnos solamente con los usuarios humanos que pueden ser identificados mediante un perfil (p.e. https://en.wikipedia.org/wiki/User:Arjuno3).
Este proceso puede tardar unas horas en ejecutarse y genera un fichero que contiene datos de más de 110 millones de ediciones, ocupando unos 5,6 GB, un tamaño respetable pero mucho más manejable que el fichero original en formato xml.
En una próxima entrada estableceremos los criterios que definirán el análisis realizado y filtraremos el fichero generado para quedarnos solamente con un subconjunto de usuarios registrados no bots y ediciones. Una primera inspección nos revela que el fichero contiene datos de más de 5 millones de páginas diferentes, teniendo en cuenta todos los espacios de nombres que constituyen Wikipedia:
cut -d’ ‘ -f1 ediciones.temp_0 | uniq | sort | uniq | wc
Para acabar, unas preguntas sobre la sentencia anterior: ¿Por qué creéis que usamos uniq antes del comando sort? ¿Habría alguna diferencia si no estuviera? ¿Es realmente necesario el segundo uniq?
NOTAS
Para este ejercicio se han usado las siguientes herramientas:
wget: es una herramienta libre del ecosistema GNU para el acceso a recursos web. Se instala fácilmente desde Homebrew, un gestor de paquetes para macOS que resulta muy útil, por lo que se recomienda también instalarlo.
mw: se trata de una librería escrita en python para la manipulación de dumps de Wikipedia.