Diferencias de género en la Wikipedia en español (III)
28 mayo, 2020
En una entrada anterior habíamos visto cómo obtener un fichero de texto con todas las ediciones realizadas en la Wikipedia en español, conteniendo solamente la información que nos interesa: de qué página se trata, el timestamp indicando el momento cuando se realizó la edición, qué usuario realizó la edición y el tamaño resultante de la página después de la edición.
El siguiente paso que abordamos en este ejercicio consiste en reducir dicho fichero, todavía enorme, eliminando todas aquellas entradas que no nos interesan para nuestro objetivo final, el cual no es otro que analizar las posibles diferencias de género entre los editores. Esto no nos interesa desde el inicio de Wikipedia, sino desde hace, por ejemplo, 5 años (de hecho, desde el 2015 en adelante). Por lo tanto, el siguiente paso es filtrar el fichero obtenido en el ejercicio anterior para:
- Eliminar entradas anteriores a 01/01/2015.
- Eliminar entradas identificadas por una dirección IP (y no por un usuario registrado).
- Eliminar entradas realizadas por bots.
Para ello usaremos una combinación de herramientas, básicamente awk y grep, pero antes procederemos a obtener la lista de bots de Wikipedia en español. Para ello nos aprovecharemos que todos los bots se encuentran categorizados como tales mediante una categoría específica en Wikipedia:
https://es.wikipedia.org/wiki/Categoría:Wikipedia:Bots
Está página de Wikipedia contiene, en el momento de realizar este ejercicio, 9 subcategorías y 472 páginas, apuntando a cada uno de los bots. Para obtener los nombres de los bots tenemos diferentes opciones: la más sencilla, si pensamos que este ejercicio solo lo vamos a ejecutar una vez, consiste en cortar y pegar los nombres de los usuarios presentes en esta página web, para obtener un fichero de texto que contenga un bot en cada línea:
.snoopybot.
Acebot
Addihockey10 (automated)
AddihockeyBot
Africanus
AgeticBOT
...
Otra opción más interesante y automatizable es aprovecharse de una opción llamada “Todas las páginas” que se encuentra en una caja debajo del apartado Subcategorías. Este enlace nos lleva a una herramienta que nos permite hacer consultas a la estructura jerárquica de categorías y subcategorías de Wikipedia.
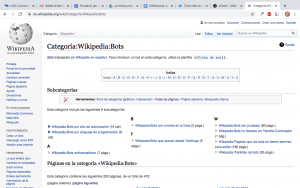
Una vez en la página de PetScan (una herramienta de Wikimedia ToolForge) hemos de seleccionar las diferentes opciones:
- En la pestaña “Page properties” marcaremos solamente la opción “Usuario”, dado que es lo que precisamente queremos, la lista de usuarios categorizados como bots.
- En la pestaña “Output” indicaremos que queremos un fichero .csv como formato de salida.
- En la pestaña “Categories” indicaremos “0” en el campo “Depth” dado que no necesitamos recorrer ninguna estructura jerárquica de subcategorías.
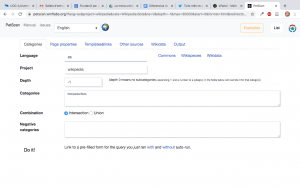
Mediante el botón “Do it!” (que cuesta de localizar) podemos ejecutar y obtener un fichero llamado “descarga.csv” con los datos requeridos (el nombre puede variar en función del navegador utilizado). Aunque no es el objetivo de este ejercicio, es muy recomendable explorar las opciones que proporciona esta herramienta, dado que es muy potente y nos permite pasearnos por la estructura de páginas de Wikipedia de forma relativamente sencilla.
El fichero “descarga.csv” contiene diversos campos separados por comas con información sobre los usuarios (en este caso bots), pero solo nos interesa el segundo, el cual contiene el nombre del usuario entre comillas. Combinando un par de comandos cut podemos quedarnos con la lista de bots en un fichero (también llamado bots) sin las comillas:
cut -d',' -f2 descarga.csv | cut -d'"' -f2 > bots
Una vez obtenida la lista de bots, procederemos a filtrar el fichero obtenido en el ejercicio anterior según los criterios acordados:
cat ediciones.temp_0 |
awk -F' ' '{if ($2>=20150101000000) print $0}' | egrep -v " ([0-9]{1,3}[\.]){3}[0-9]{1,3} " |??? … > ediciones.dat
La primera sentencia awk es muy simple: primero se especifica que el separador usado en el fichero es el espacio (carácter ‘ ‘), y luego una simple sentencia if solo imprime aquellas líneas ($0 representa el registro entero, es decir, una línea del fichero) que cumplan la condición especificada, es decir, que el segundo campo ($2, el timestamp) sea mayor o igual a la primera fecha que queremos. Esto se aprovecha de que el formato de la fecha YYYYMMDDhhmmss permite comparaciones numéricas, simplificando esta operación.
La siguiente sentencia egrep (es una extensión de grep incluyendo expresiones regulares) elimina (mediante -v, que invierte el resultado) todas las líneas que contengan el patrón nnn.nnn.nnn.nnn donde nnn es cualquier número entre 0, 00 o 000 y 9, 99 o 999, dado que se trata direcciones IP v4 de usuarios que editan anónimamente. Es importante observar que no todos estos patrones corresponden a direcciones IP válidas, pero ya es suficiente para nuestro cometido. El primer espacio antes del paréntesis y el último son un recurso sencillo para asegurar que solo filtramos usuarios y no páginas, al no empezar éstas por un espacio.
Filtrar direcciones IP v6 es un poco más complicado. En este caso, la expresión regular que define todas las posibilidades que puede adoptar una dirección IP v6 es:
egrep -v “ (([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:)
{1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:)
{1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4})
{1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:)
{1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4})
{1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}
%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|
1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])
|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.)
{3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])) ”Este paso es indispensable, dado que el uso de direcciones IP v6 es ya una realidad y de hecho en el fichero de ediciones aparecen muchas identificadas con dicho formato, por lo que es necesario filtrarlas.
Finalmente, como última sentencia a ejecutar, para filtrar y eliminar las ediciones realizadas por bots una opción sencilla podría ser usar “grep -v -f bots”, pero esto presenta un par de problemas. El primero es que grep busca el patrón en toda la línea, no solamente en el tercer campo (el usuario), por lo que si una página coincide parcialmente con el nombre de un bot también sería eliminada. El segundo problema es que el uso de “-f” es especialmente lento, lo que es un problema con un fichero de varios millones de líneas, como es el caso.
En su lugar usaremos un sencillo script awk que realiza exactamente la operación deseada: primero carga el fichero de bots y luego filtra aquellas líneas que contienen el nombre de un bot en el tercer campo:
BEGIN {FS=" "
while ((getline line < "bots") > 0) {bot[line]=1
}
}
{if (bot[$3]!=1) print $0
}
El bloque BEGIN { … } se ejecuta una sola vez antes del primer registro de entrada (es decir, de la primera línea del fichero de entrada). Primero se ajusta el separador entre campos (FS, de Field Separator) al espacio, y luego un sencillo bucle lee todas las líneas del fichero “bots”, una cada vez, y crea un array asociativo llamado bot donde aquellas entradas que se hayan leído valdrán 1. El bloque { … } se ejecuta una vez por cada línea y básicamente comprueba que el usuario (en la tercera posición de acuerdo al separador especificado) no sea un bot, imprimiendo la línea entera en este caso.
El resultado es un fichero llamado ediciones.dat que contiene casi 23 millones de ediciones realizadas por más de medio millón de usuarios registrados. Como es habitual, una gran cantidad de usuarios solamente realiza una edición, mientras que unos pocos superan los miles de ediciones. Para reducir el análisis a un número de usuarios razonable, nos quedaremos con aquellos usuarios que hayan realizado, al menos, 50 ediciones. Esto reduce el fichero original a uno más manejable con casi 21 millones de ediciones realizadas desde el 01/01/2015 por 17752 usuarios registrados en casi 2 millones y medio de páginas diferentes (incluyendo todos los namespaces de Wikipedia).
Como ejercicio para el lector se propone combinar las dos sentencias awk y las sentencias grep intermedias en un solo script awk que realice todas estas operaciones, aunque también podría realizarse en Python, así como la realización del último paso donde se seleccionan solamente las ediciones de aquellos usuarios registrados que hayan realizado al menos 50 ediciones.