
Explicabilidad en la visión por computador
23 marzo, 2021
(Més avall trobareu la versió en català d’aquest contingut.)
Los programas informáticos son cada vez más capaces de tomar decisiones por sí solos. Ya no nos sorprende que podamos dialogar con una máquina o que los coches se muevan sin conductor. Los algoritmos de aprendizaje automático están detrás de estas mejoras al permitir que las máquinas generalicen comportamientos.
Uno de los campos que se está beneficiando más de estos avances es la visión por computador. Para fijarnos en estos cambios nos centraremos en un ejemplo concreto: la clasificación de imágenes. En la clasificación de imágenes, el problema consiste en detectar a qué clase pertenece una imagen dentro de un conjunto de clases. Por ejemplo, supongamos que tenemos imágenes de objetos y lo que queremos es un sistema que, al ver una imagen, pueda reconocer qué objeto es el que se muestra en la imagen. En este caso, el algoritmo analiza la imagen y le asigna una categoría: persona, gato, perro, coche, … Se trata de un problema de aprendizaje supervisado: se entrena un modelo mediante fotos de ejemplo que una persona ha etiquetado previamente.
Uno de los retos en los algoritmos de aprendizaje artificial es que, además de dar una respuesta al problema planteado, nos den una justificación de por qué han dado aquella respuesta en concreto: la explicabilidad.
Por ejemplo, imaginemos que tenemos un conjunto de imágenes de perros:

Y otras de gatos:

Un buen algoritmo de clasificación de imágenes será aquel que aprenda a clasificar imágenes en cada clase:
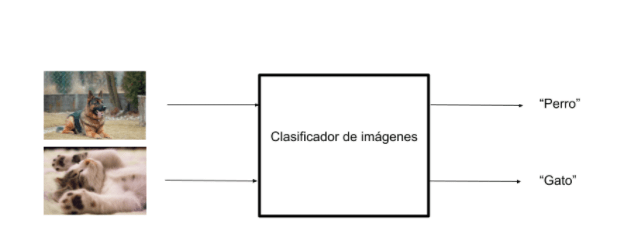
Esta tecnología se utiliza en la búsqueda de fotos personales, en la que los usuarios pueden buscar de entre todas las fotos de la biblioteca aquellas donde aparece una categoría determinada. Utilizaremos este ejemplo para motivar la explicabilidad en el aprendizaje automático.
Métodos tradicionales de visión por computador
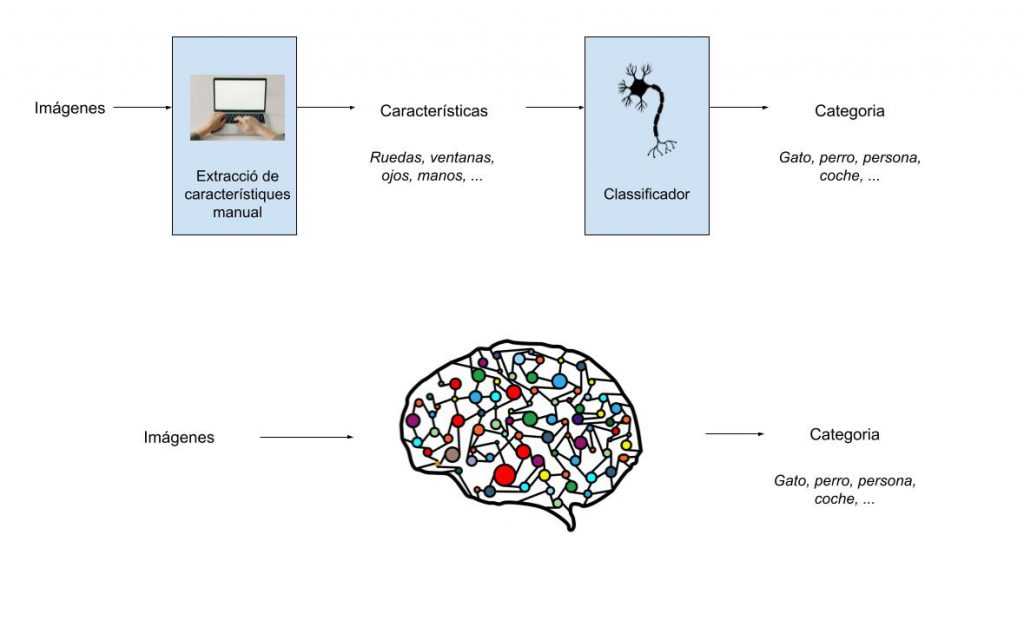
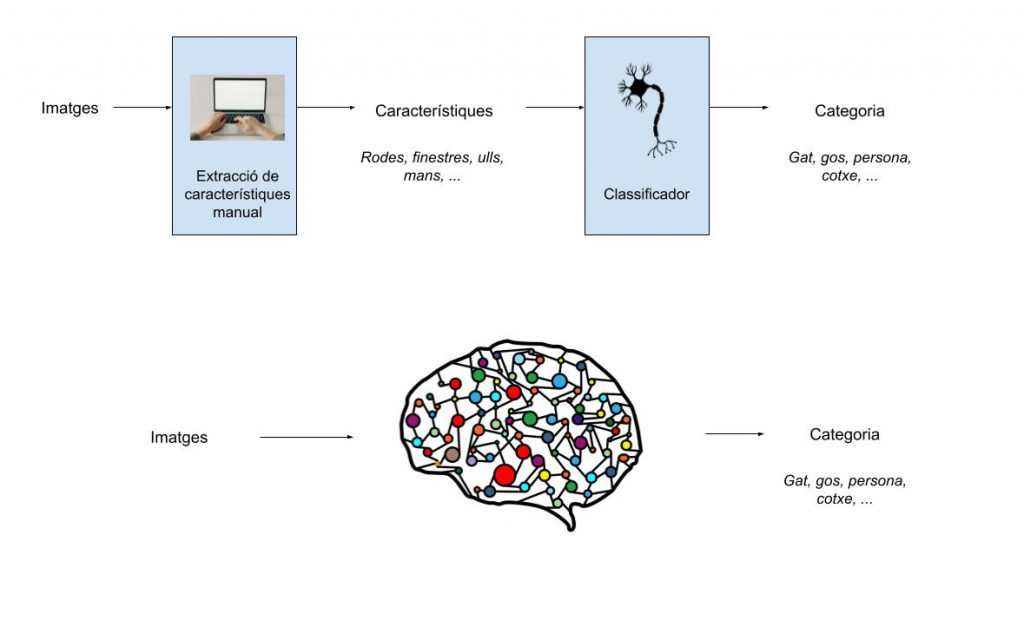
Durante muchos años, los problemas de visión por computador se resolvían en dos etapas diferenciadas: primero se extraían una serie de características o patrones y luego se clasificaban estas características entre las diversas categorías. Este paradigma permitía una explicabilidad de los resultados ya que los patrones a buscar se diseñaban a mano. Por ejemplo, la parte de extracción de patrones podía detectar puntos característicos de los objetos a identificar (ruedas, ventanas, ojos, manos, …). En una etapa posterior, el clasificador decidía a qué objeto pertenecían estas características: si en una imagen tenemos unas cuantas ruedas y ventanas el clasificador decide que es un coche. En cambio, si tiene ojos y manos, el algoritmo nos dirá que es una persona.
En este paradigma, ¡los humanos entendemos qué ha hecho el algoritmo!
Revolución del aprendizaje profundo
Todo esto cambió cuando un algoritmo basado en aprendizaje profundo obtuvo una gran mejora respecto de los algoritmos basados en extracción de características + clasificación. Entendemos como aprendizaje profundo aquellos modelos que, en lugar de separar entre dos etapas, están basados en múltiples capas (redes neuronales) que directamente nos dan un resultado. Llamamos este paradigma aprendizaje profundo (deep learning) ya que están formados con un gran número de capas.
Esta imagen ilustra la diferencia entre los dos paradigmas:
Para tener una visión de la mejora obtenida podemos centrarnos en el problema de la clasificación de imágenes. Este problema fue el primero en disfrutar de la revolución del aprendizaje profundo. Podemos ver la evolución en el siguiente gráfico que muestra el error medio del mejor modelo utilizando la base de datos ImageNet:
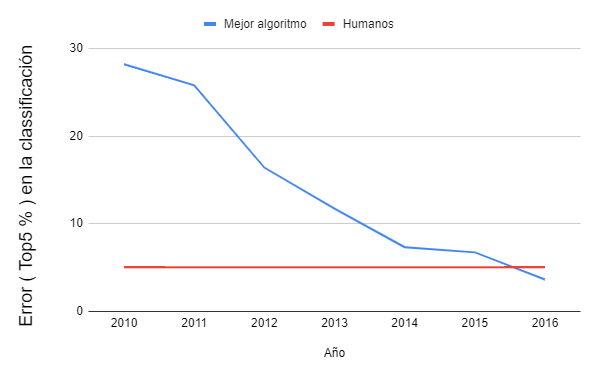
Los modelos previos 2011 utilizaban extracción de características más un clasificador. El año 2012 fue el primero en el que se introdujo un modelo de aprendizaje profundo. ¡El uso de aprendizaje profundo ha permitido bajar la tasa de error del 25% a menos de un 5%, mejor que los humanos!
El aprendizaje profundo ha conseguido mejoras tan notables que se ha convertido en la solución a muchos problemas industriales. Por lo tanto, cada vez más problemas se solucionan con esta metodología: sistemas que se entrenan de extremo a extremo, muchas veces sin entender qué está haciendo el algoritmo. Son algoritmos que actúan como cajas negras: sabemos que a la entrada colocamos una imagen y que a la salida nos dan la categoría pero ¡no entendemos qué pasa dentro de la caja!
¿Por qué necesitamos que estos procesos sean explicables?
Un ejemplo para motivar la explicabilidad es un sistema automático para ayudar al diagnóstico cardiovascular mediante imágenes médicas. Cuando el algoritmo detecte un alto riesgo de incidente cardíaco y la necesidad de una intervención urgente, es deseable que nos dé una explicación de esta predicción. Como humanos, nos gustaría una explicación consistente por parte del algoritmo: usted necesita una operación porque casos clínicos similares, basados en la ubicación y la tasa de estenosis coronaria, lo indican. Si deseas profundizar más en un ejemplo médico, puedes acceder al siguiente artículo sobre diagnóstico de enfermedades a partir de imágenes de Rayos X.
Como sociedad entendemos que las personas cometemos errores pero no podemos aceptar que los algoritmos lo hagan y no sepamos porque! Actualmente, en el aprendizaje profundo, el resultado de estos algoritmos no es explicable: no podemos explicar qué ha fallado en la decisión. Por tanto, a pesar de que han demostrado ser muy útiles, los modelos de aprendizaje profundo funcionan como cajas negras. Lo que nos lleva a hacernos la pregunta: ¿podemos construir modelos explicables?
Un modelo explicable debería tener las siguientes características:
- Interpretable: comprensible para los humanos
- Completo: debe proporcionar decisiones predecibles en situaciones similares
- Auditable: permite comprender y revisar el comportamiento del algoritmo
La explicabilidad no sólo ayuda a asegurar la confianza de los usuarios, también tiene ventajas técnicas ya que ayuda a comprender las relaciones de causa y obtener un conocimiento más profundo del problema, permitiendo desarrollar mejores algoritmos.
Construyendo modelos explicables
Para ser plenamente adoptados para la sociedad, los modelos de aprendizaje profundo deben ser comprensibles, éticos y seguros. Hacer posible que estos modelos sean explicables es una línea de investigación del grupo SUnAI de la UOC.
Unas de las preguntas que debemos responder son:
- ¿Se pueden diseñar métodos de aprendizaje profundo teniendo en cuenta no sólo la precisión, sino también su explicabilidad? Es decir, ¿por qué una entrada determinada conduce a una salida en concreto?
- Representación interna de la red: ¿qué información contiene la red sobre los datos? ¿Qué sabe del mundo para tomar las decisiones? Por ejemplo, este artículo del blog muestra una red que para reconocer escenas aprende a detectar qué objetos aparecen.
Debemos asegurar que los algoritmos mantienen la vertiente humana de las explicaciones para poder confiar en ellos. Los usuarios de algoritmos deben interactuar con el sistema pudiendo comprender qué hace y porqué lo hace. Trabajar con algoritmos explicables también facilita la depuración y mejora del sistema a los desarrolladores. Y la explicabilidad no sólo es útil para aplicaciones concretas, como sociedad, los modelos explicables nos permiten poder construir un mundo donde podemos asegurar que se cumplen unos estándares de fiabilidad y de ética.
Explicabilitat en la visió per computador

Els programes informàtics cada cop són més capaços de prendre decisions per si sols. Ja no ens sorprèn que puguem dialogar amb una màquina o que els cotxes es moguin sense conductor. Els algorismes d’aprenentatge automàtic estan darrere d’aquestes millores al permetre que les màquines generalitzin comportaments.
Un dels camps que s’està beneficiant més d’aquest avenços és la visió per computador. Per fixar-nos en aquests canvis ens centrarem en un exemple concret: la classificació d’imatges. En la classificació d’imatges, el problema consisteix en detectar a quina classe pertany una imatge dins d’un conjunt de classes. Per exemple, imaginem que tenim imatges d’objectes i el que volem és un sistema que, al veure una imatge, pugui reconèixer quin objecte és el que es mostra a la imatge. En aquest cas, l’algorisme analitza la imatge i li assigna una categoria: persona, gat, gos, cotxe,… Es tracta d’un problema d’aprenentatge supervisat: s’entrena un model mitjançant fotos d’exemple que una persona ha etiquetat prèviament.
Un dels reptes en els algorismes d’aprenentatge artificial és que, a part de donar una resposta al problema plantejat, ens donin una justificació de perquè han donat aquella resposta en concret: l’explicabilitat.
Per exemple, imaginem que tenim un conjunt d’imatges de gossos:
I altres de gats:

Un bon algorisme de classificació d’imatges serà aquell que aprengui a classificar imatges en cada classe:
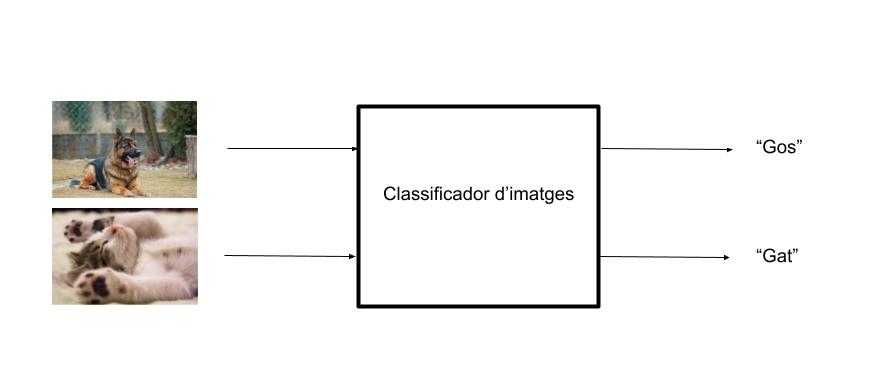
Aquesta tecnologia s’utilitza en la cerca de fotos personals, en la que els usuaris podem buscar d’entre totes les fotos de la biblioteca aquelles on apareix una categoria determinada. Utilitzarem aquest exemple per motivar l’explicabilitat en l’aprenentatge automàtic.
Mètodes tradicionals de visió per computador
Durant molts anys, els problemes de visió per computador es resolien en dues etapes diferenciades: primer s’extreien una sèrie de característiques o patrons i després es classificaven aquestes característiques entre les diverses categories. Aquest paradigma permetia una explicabilitat dels resultats ja que els patrons a buscar es dissenyaven a mà. Per exemple, la part d’extracció de patrons podia detectar punts característics dels objectes a identificar (rodes, finestres, ulls, mans, …). En una etapa posterior, el classificador decidia a quin objecte pertanyien aquestes característiques: si en una imatge tenim unes quantes rodes i finestres el classificador decideix que és un cotxe. En canvi, si té ulls i mans, l’algorisme ens dirà que és una persona.
En aquest paradigma, els humans entenem què ha fet l’algorisme!
Revolució de l’aprenentatge profund
Tot això va canviar quan un algorisme basat en aprenentatge profund va obtenir una gran millora respecte els algorismes basats en extracció de característiques + classificació. Entenem com a aprenentatge profund aquells models que, en lloc de separar entre dues etapes, estan basats en múltiples capes (xarxes neuronals) que directament ens donen un resultat. Anomenem aquest paradigma aprenentatge profund (deep learning) ja que estan formats amb un gran nombre de capes.
Aquesta imatge ilustra la diferència entre els dos paradigmes:
Per tenir una visió de la millora obtinguda ens podem centrar en el problema de la classificació d’imatges. Aquest problema va ser el primer en gaudir la revolució de l’aprenentatge profund, podem veure l’evolució en el següent gràfic que mostra l’error mitjà del millor model utilitzant la base de dades ImageNet:
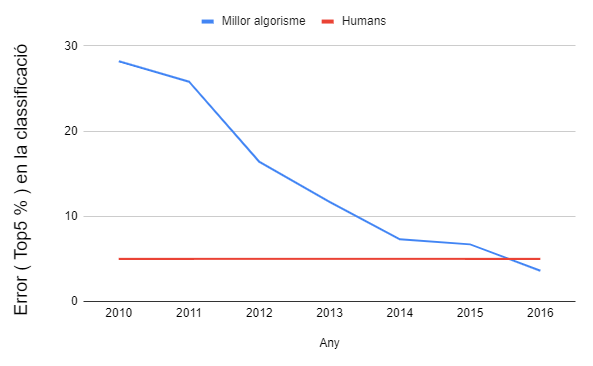
Els models previs a 2011 utilitzaven extracció de característiques més un classificador. L’any 2012 va ser el primer que es va introduir un model d’aprenentatge profund. L’ús d’aprenentage profund ha permès baixar la taxa d’error del 25% a menys d’un 5%, millor que els humans!
L’aprenentatge profund ha aconseguit millores tan notables que s’ha convertit en la solució a molts problemes industrials. Per tant, cada cop més problemes es solucionen amb aquesta metodologia: sistemes que s’entrenen d’extrem a extrem, molts cops sense entendre que està fent l’algorisme. Són algorismes que actuen com caixes negres: sabem que a l’entrada col·loquem una imatge i que a la sortida ens donen la categoria però no entenem que passa entremig!
Per què necessitem que aquests processos siguin explicables?
Un exemple per motivar l’explicabilitat és un sistema automàtic per ajudar al diagnòstic cardio-vascular mitjançant imatges mèdiques. Quan l’algorisme detecti un alt risc d’incident cardíac i la necessitat d’una intervenció urgent, és desitjable que ens doni una explicació d’aquesta predicció. Com a humans, ens agradaria una explicació consistent per part de l’algorisme: vostè necessita una operació perquè similars casos clínics basats en la ubicació i la taxa d’estenosi coronària ho indiquen. Si voleu aprofundir més en un exemple mèdic, podeu llegir aquest article sobre diagnòtic de malalties mitjançant imatges de Raigs X.
Com a societat, entenem que les persones cometem errors però no podem acceptar que els algorismes ho facin i no saber el perquè! Actualment, en l’aprenentatge profund, el resultat d’aquests algorismes no és explicable: no podem explicar què ha fallat en la decisió. Per tant, tot i que han demostrat ser molt útils, els models d’aprenentatge profund funcionen com a caixes negres. El que ens porta a fer-nos la pregunta: podem construir models explicables?
Un model explicable hauria de tenir les característiques següents:
- Interpretable: comprensible per als humans
- Complet: ha de proporcionar decisions predictibles en situacions similars
- Auditable: permet comprendre i revisar el comportament de l’algorisme
L’explicabilitat no només ajuda a assegurar la confiança dels usuaris, també té avantatges per la tècnica ja que ajuda a comprendre les relacions de causa i obtenir un coneixement més profund del problema, permetent desenvolupar millors algorismes.
Construint models explicables
Per tal de ser plenament adoptats per a la societat, els models d’aprenentatge profund han de ser comprensibles, ètics i segurs. Fer possible que aquests models siguin explicables és una línea de recerca del grup SUnAI de la UOC .
Unes de les preguntes que cal fer-nos són:
- Es poden dissenyar mètodes d’aprenentatge profund tenint en compte no només la precisió, sinó també la seva explicabilitat? És a dir, per què una entrada determinada condueix a una sortida en concret?
- Representació interna de la xarxa: quina informació conté la xarxa sobre les dades? Que sap del món per prendre les decisions? Per exemple, en aquest article del blog s’ensenya una xarxa que per reconèixer escenes apren a detectar quins objectes hi apareixen.
Hem d’assegurar que els algorismes mantenen la vessant humana de les explicacions per poder-hi confiar. Els usuaris d’algorismes han d’interactuar amb el sistema podent comprendre què fa i per què ho fa. Treballar amb algorismes explicables també facilita la depuració i millora del sistema als desenvolupadors. I l’explicativitat no només és útil per aplicacions concretes, com a societat, els models explicables ens permeten poder construir un món on podem assegurar que es compleixen uns estàndards de fiabilitat i d’ètica.


